基本信息
| 会议/期刊 | ICLR |
|---|---|
| 年份 | 2021 |
| 机构 | 西安电子科技大学 |
| 一作 | Yige Li |
| 领域 | AI Security, Backdoor Attack, Backdoor Defense, Knowledge Distillation |
主要贡献
本文结合注意力蒸馏方法与后门防御策略,提出了一种新的模型后门清除方法Neural Attention Distillation(NAD)。NAD仅需5%的训练集数据,先对backdoored model进行fine-tune,得到teacher,然后再把backdoored model当作student,使用注意力蒸馏方法,固定teacher并训练student。NAD能有效清除6种后门攻击的影响(BadNets、Trojan、Blend、CL、SIG、Refool),并能保持模型在正常数据上的准确率受影响较小。实验表明,NAD算法在ASR和ACC上都超过了fine-tune和剪枝。
背景
已有工作
backdoor attack的背景recap
- 经典威胁模型
- 收集到不可信的数据
- 下载到不可信的预训练模型
- 攻击方式分类
- 按是否直接修改label,分为poisoned-label attack和clean-label attack
- trigger pattern分类
- trigger pattern包括pixel、patch、sinusoidal strips、dynamic patterns、natural reflection、human imperceptible noise等等
- 比较特殊的场景:训练集未知、联邦学习等
backdoor defense的challenge
- 检测后门样本:不可见的or利用reflection的后门样本很难在test阶段被检测到
- 重训练/剪枝:很难完全清除后门,效果还很局限
- 检测trigger:即使还原出trigger,也需要后门清除算法
结论
后门清除效果
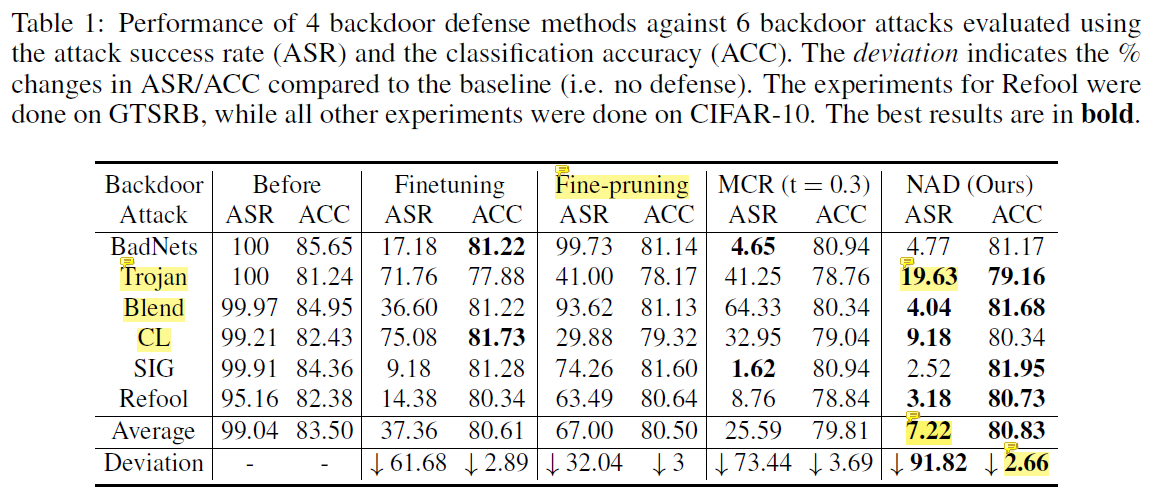
- Trojan经过NAD后还有19%的攻击成功率,还有提升空间
- NAD对Trojan、Blend、CL这三种攻击方法的效果远远超过其他几种方法
- 经过NAD清除后的后门平均保留了7.22%的攻击效果,还有进步空间
- NAD方法的另一大优势是牺牲的ACC指标最小,猜测这应该是KD的功劳,并且也要看KD阶段使用的数据集质量
- MCR对complicated adversarial noises的后门攻击效果不好
- fine-tuning时使用的data augmentation可能起到unlearning的作用
- fine-pruning效果不好,原因可能是WRN-16-1的最后一层神经元数目太少,混杂了benign neurons和backdoored neurons,导致剪枝会影响ACC
fine-tune和KD阶段使用的数据量的影响

为什么Attention Map比Feature Map更好?

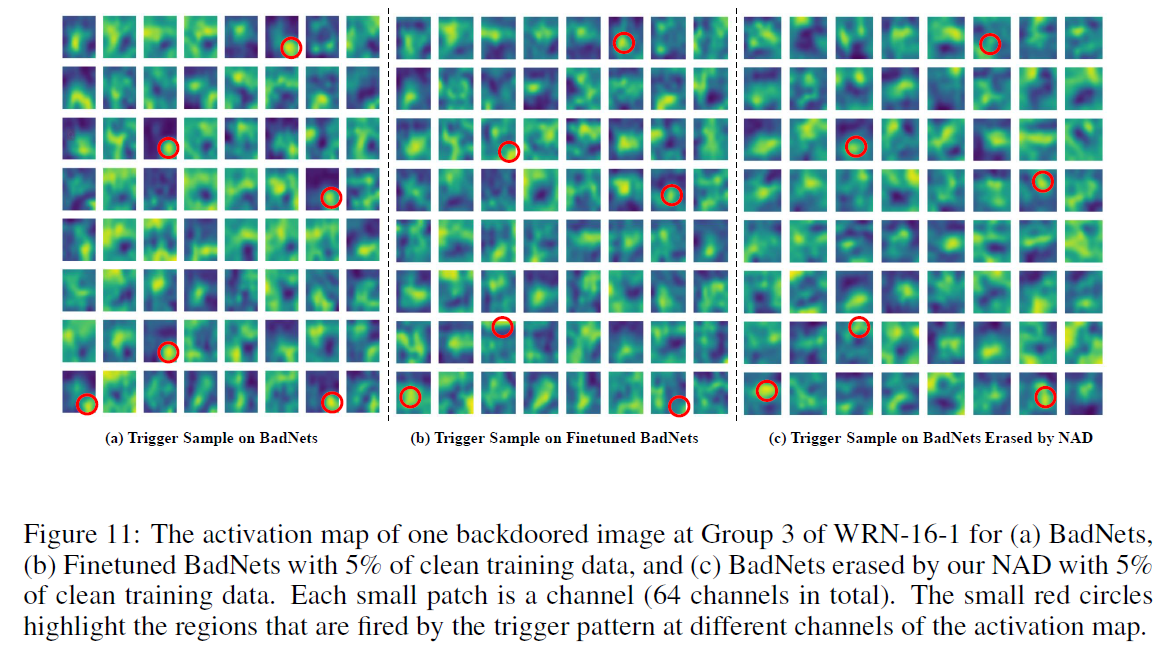
- 从图3可以看出,后门攻击中,attention map很明显会暴露出trigger region
- 从图11可以看出,trigger的信息在activation map中很分散
- 如果使用feature map而不是attention map,会导致information loss on the sample density in the space,并且降低了蒸馏效果
Directly aligning the feature maps could lead to an information loss on the sample density in the space, and this could lead to a decrement in the distillation performance (Zagoruyko & Komodakis, 2017; Huang & Wang, 2017; Lopez et al., 2019).

- NAD方法中,使用attention map效果明显比activation map效果好
- attention map中包含的trigger effect比feature map更加完整
It can thus provide an integrated measure of the overall trigger effect. On the contrary, the trigger effect may be scattered into different channels if we use the raw activation values directly.
- attention map regularization的优化比feature map更加简单
与retrain-based方法对比

- 在CL攻击下,NAD方法比retrain-based方法效果更加好
- retrain-based方法对CL攻击效果不好,retrain后ASR仍然有25%、31%,而NAD方法能将ASR降至9%
- 在BadNets攻击下,NAD方法与retrain-based方法效果差不多
使用不同的注意力计算方式对NAD性能的影响
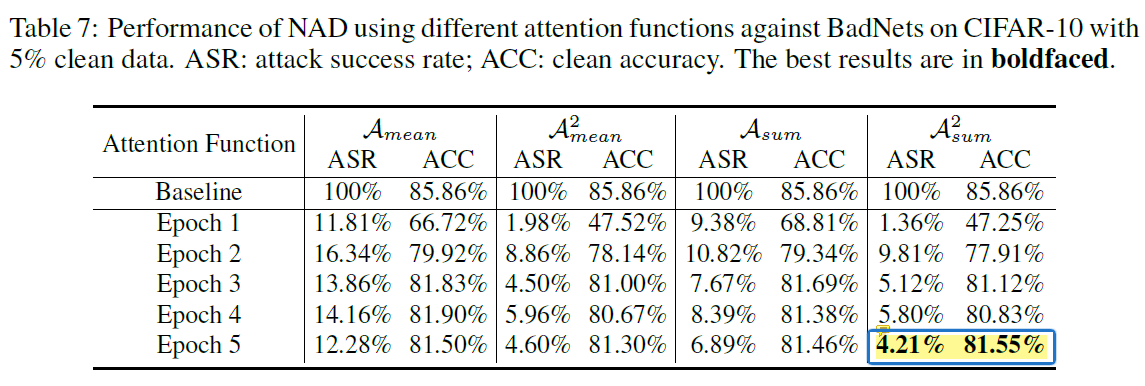
明显比其他三种更加好。
防御简单的adaptive attack
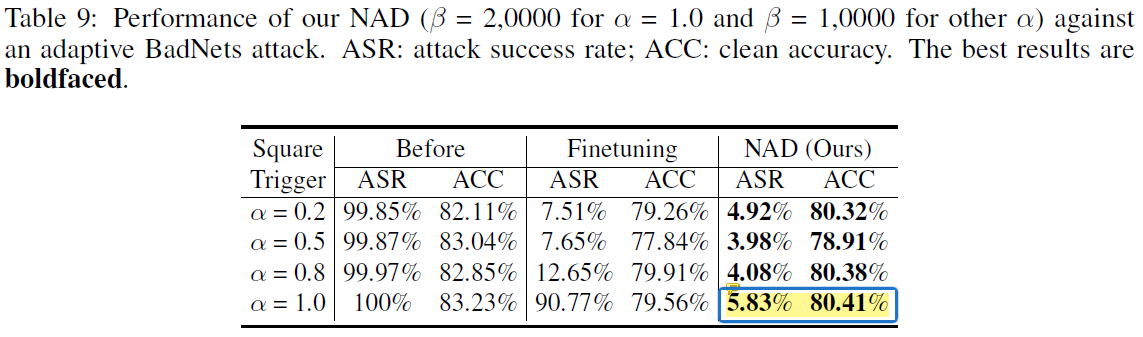
将trigger放在图像中央(CIFAR10数据集中,数据的重要信息一般都在正中间),与图像本身的attention重合,构成简单的adaptive attack。NAD对于这种攻击仍然有防御效果。
模型架构的影响
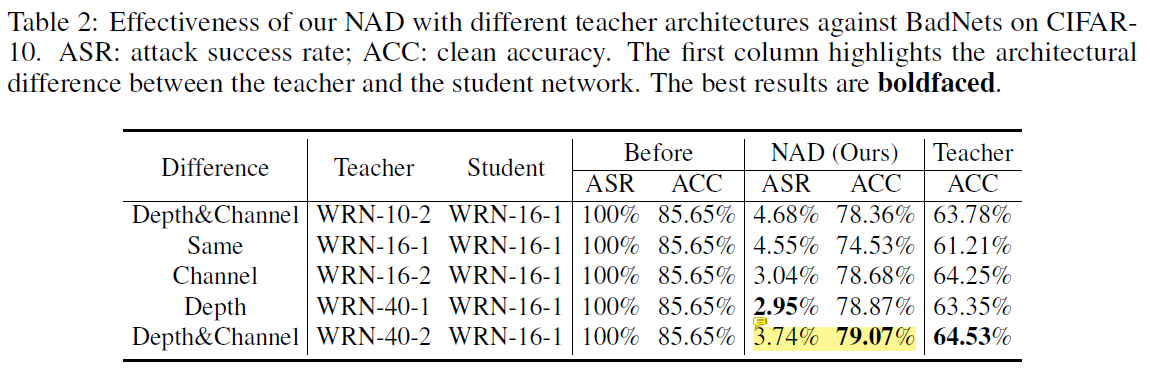
- 将多种不同架构的teacher train from scratch(只用5%的训练数据),发现NAD对多种架构的WRN网络都适用
- 本文只在WRN架构下研究
方法
NAD的思想:使容易被trigger pattern影响的神经元(backdoored neurons)与只对正常representation有反应的神经元(benign neurons)“对齐”。
NAD的主要challenge
- 如何定义proper attention representations(能区分开backdoored neurons和benign neurons)
- 如何定义attention distillation的loss function
定义attention map的计算方式
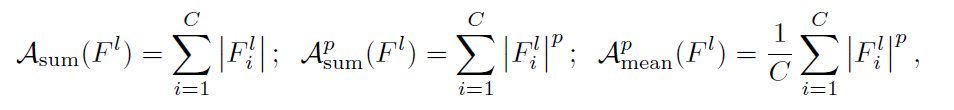

其中,参数p可以提升backdoored neurons和benign neurons之间的分别,p越大,最大的神经元激活值的权重也就越大。btw,对attention map进行normalization非常重要,对蒸馏效果影响很大。
定义注意力蒸馏的loss函数
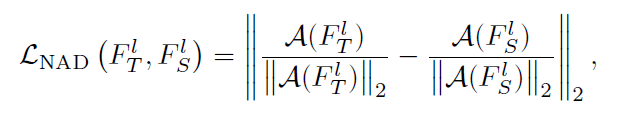
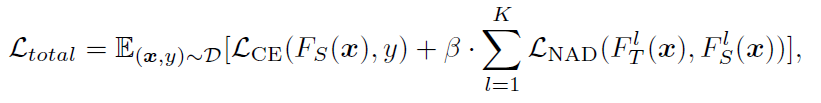
其中,D表示的是防御者拥有的数据集的子集,K表示ResNet中的Residual Group数量。
缺陷
- 实验部分使用的模型架构单一,仅涉及WRN这一系列模型
- 实验效果非常依赖数据增强的tricks
- 由于fine-tune和知识蒸馏阶段所使用的训练数据受随机选取影响,复现结果的波动特别大